AWSのAutoScalingの起動設定がAMIの入れ替えがめんどくさくて使いにくいな〜って思っていたところ、 起動テンプレートという機能があって、これが使い勝手が良い!
またこの起動テンプレートと組み合わせることで、AutoScalingの設定にもバリエーションが出てくる。
ということで早速やってみよう。
起動テンプレートの作成
EC2の左のメニューから起動テンプレートを選択
右上の「起動テンプレートを作成」から始める。
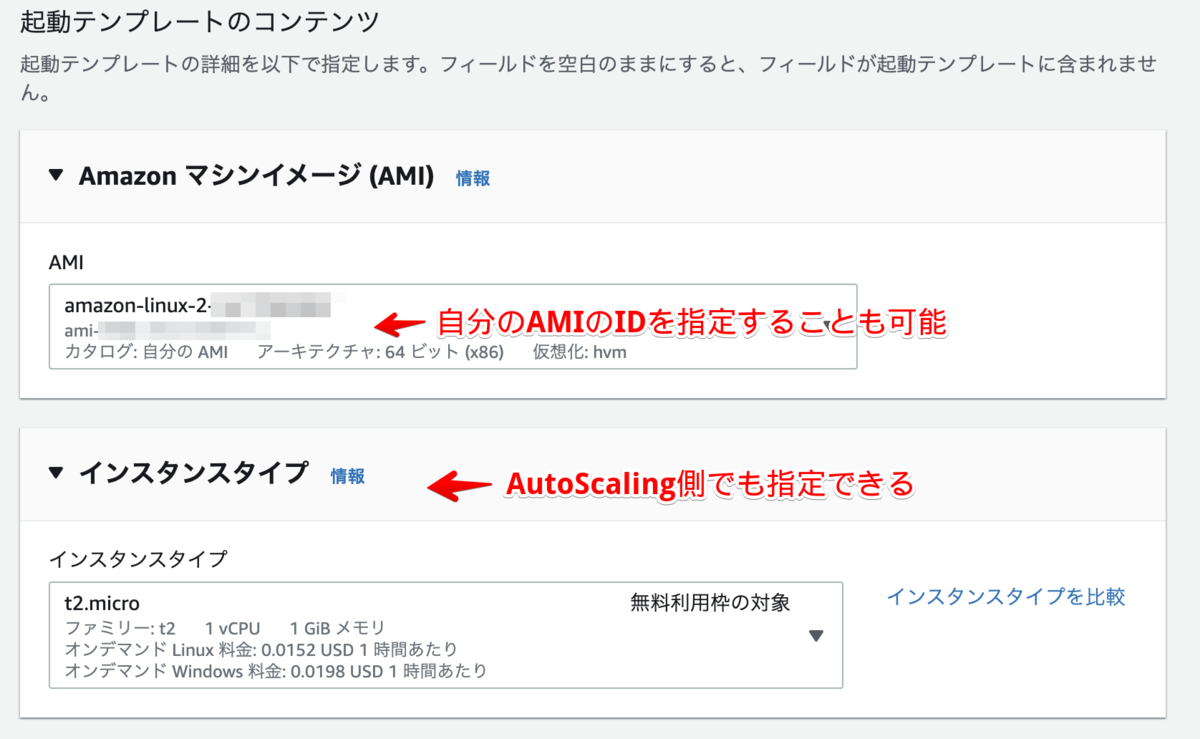
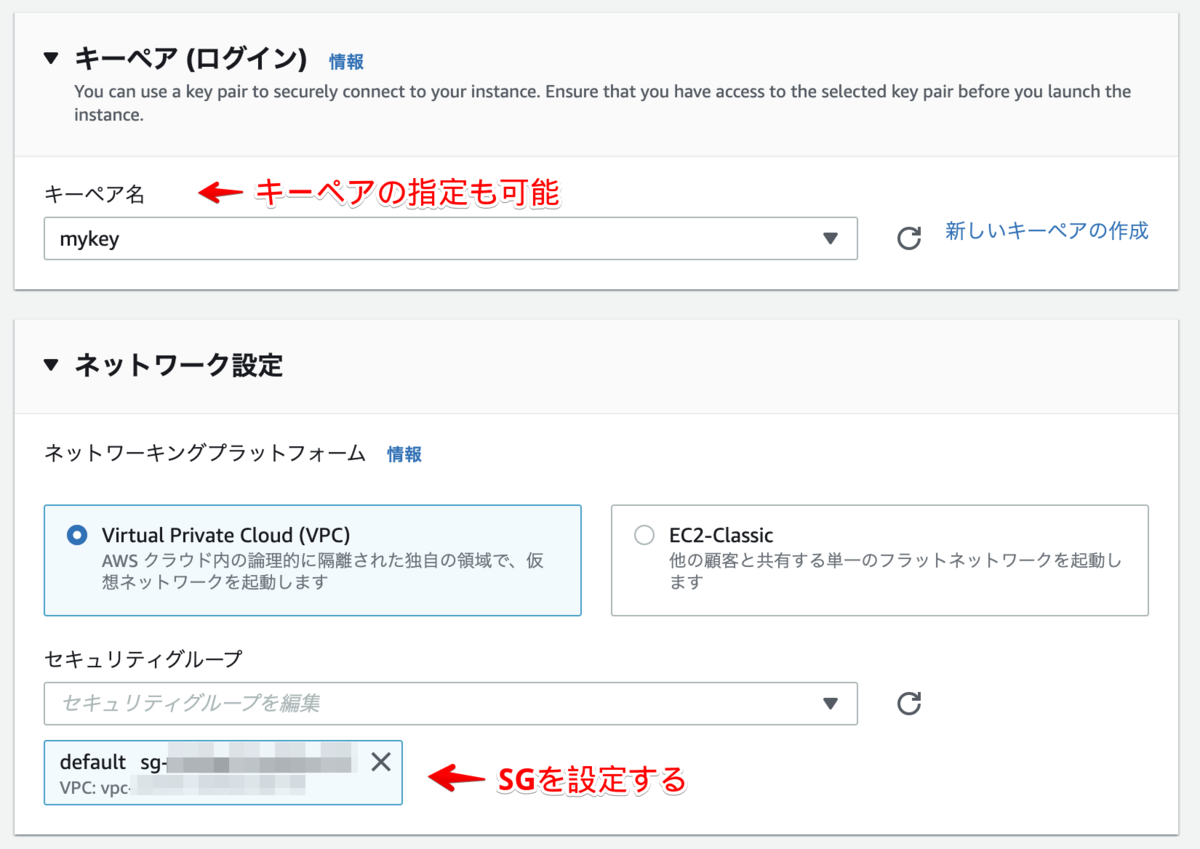
後の設定はデフォルトでオッケー。
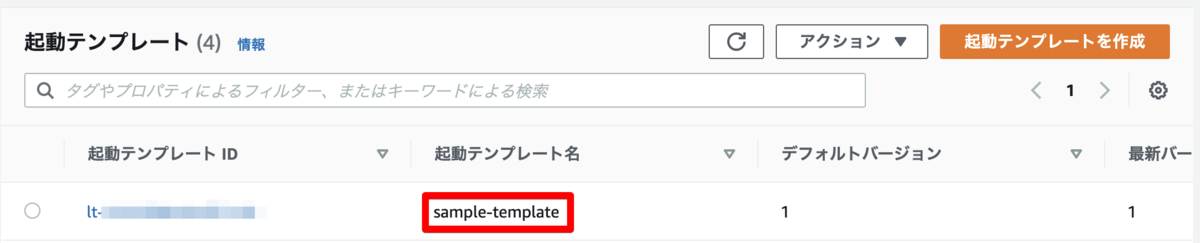
無事にテンプレートが作成できました。
次は、AutoScalingの設定。
EC2の左のメニューからAuto Scaling グループを選択

なぜかこのメニューを選ぶとメニューが英語化する。
この現象に気がついてからしばらく経つけど一向に直る気配なし。
特に困ってないし、まぁ、いいか。
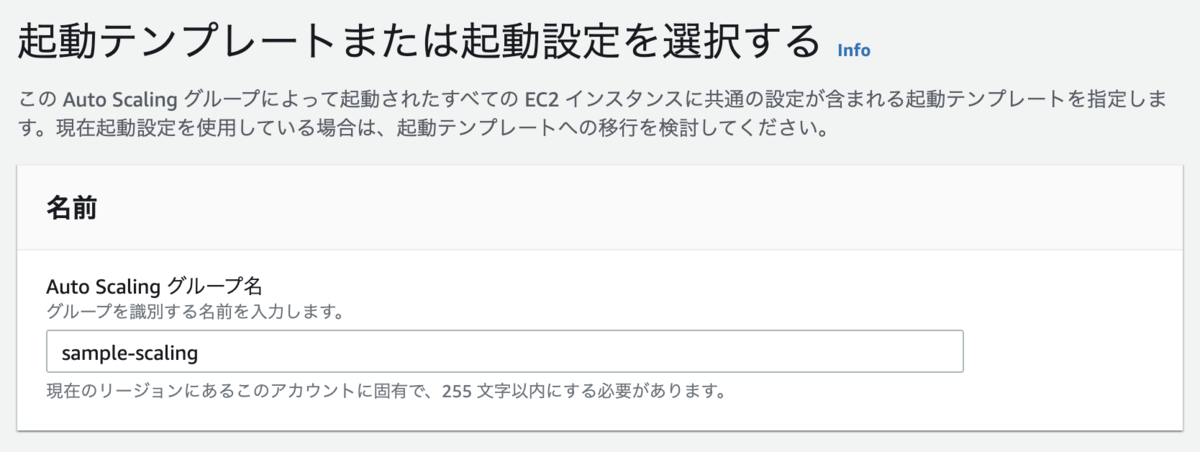
起動テンプレートには先ほどのテンプレートを。
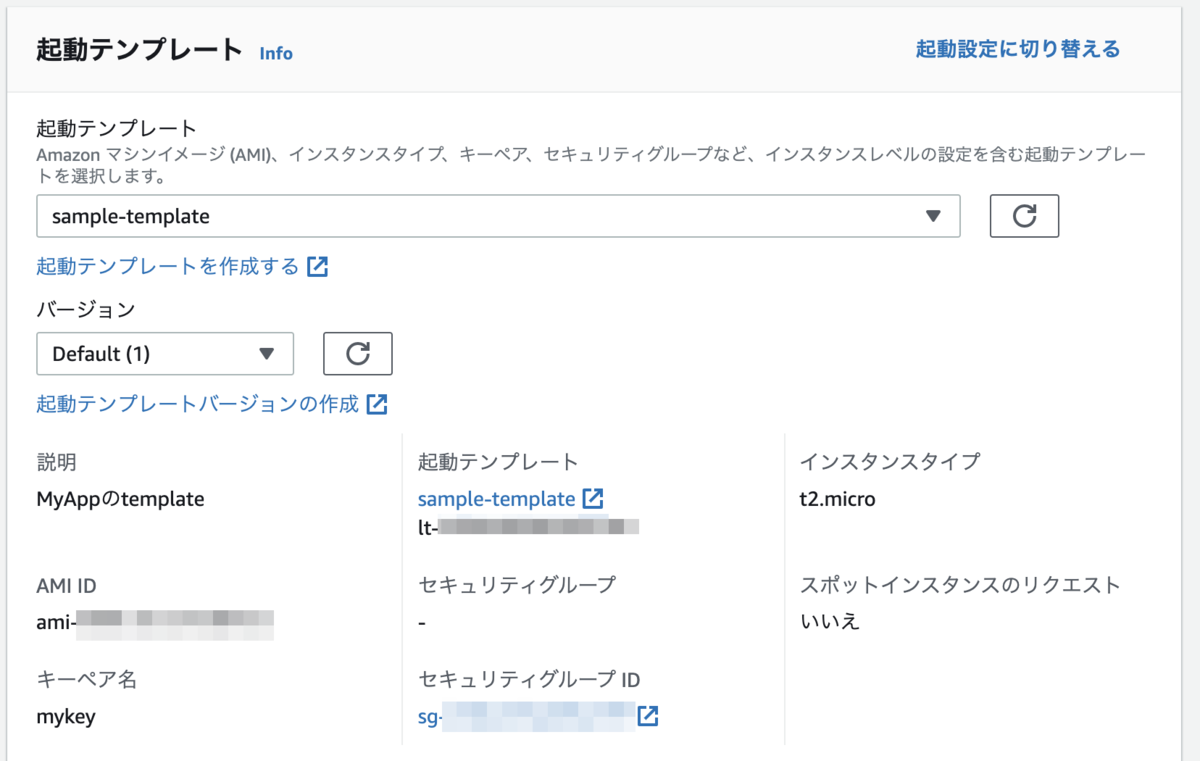
これで次へ
ここから重要。
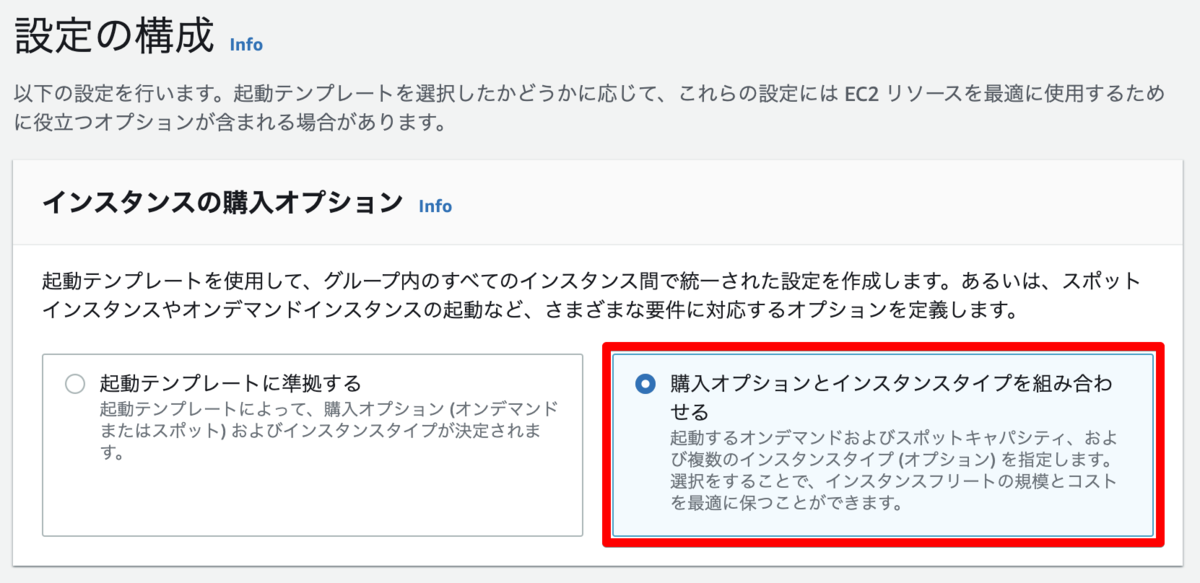
デフォルトの設定でも良いのですが、「購入オプションとインスタンスタイプを組み合わせる」を選ぶことでAutoScalingで起動するインスタンスにスポットインスタンスを取り入れることが可能になります。
これは使い方次第でかなり節約が見込めそう
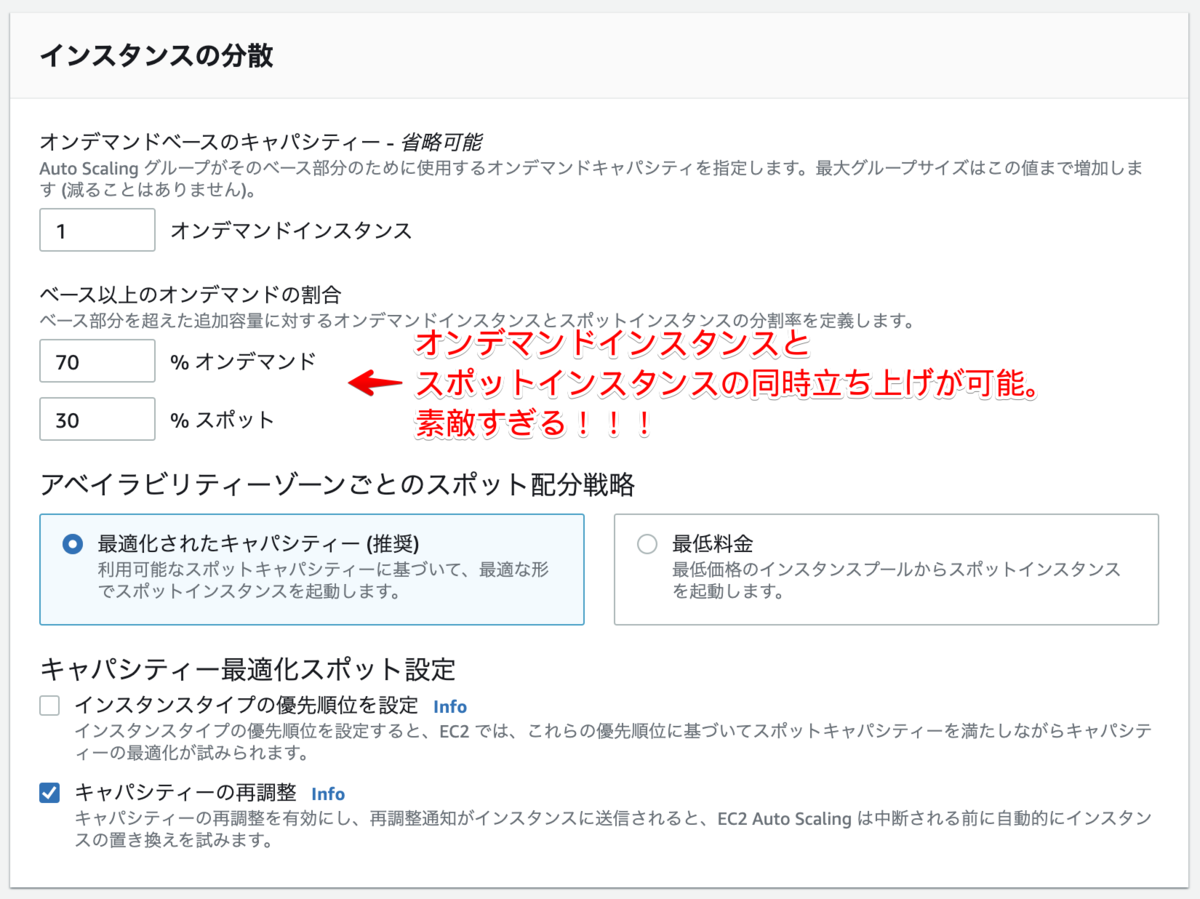
常に立ち上げておく、オンデマンドインスタンスの数と、オンデマンドとスポットの比率の調整をここで設定
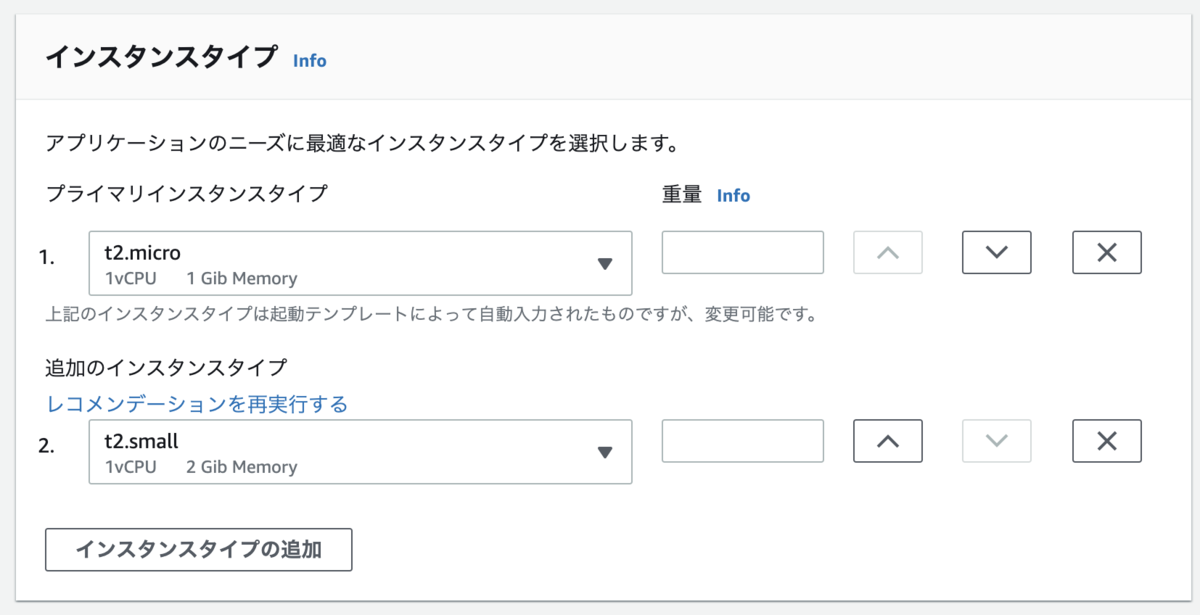
ここも重要。
スポットインスタンスを多めに使う場合は、空き容量がなくなったらそもそも立ち上がらなくなるため(立ち上がってもすぐ死んだり)、使用するインスタンスタイプを分けて優先順位をつけておくことで、必要な数立ち上がらなくなるという事態を避けることができる。この時に必要なサイズに近いもので設定しておくのが良し。m5.largeとm4.largeとか。

置き場所を選んで、次へ
(Multi AZしたい場合はSubnet2つ以上選ぶこと)
ロードバランシングは一旦なしで、次へ
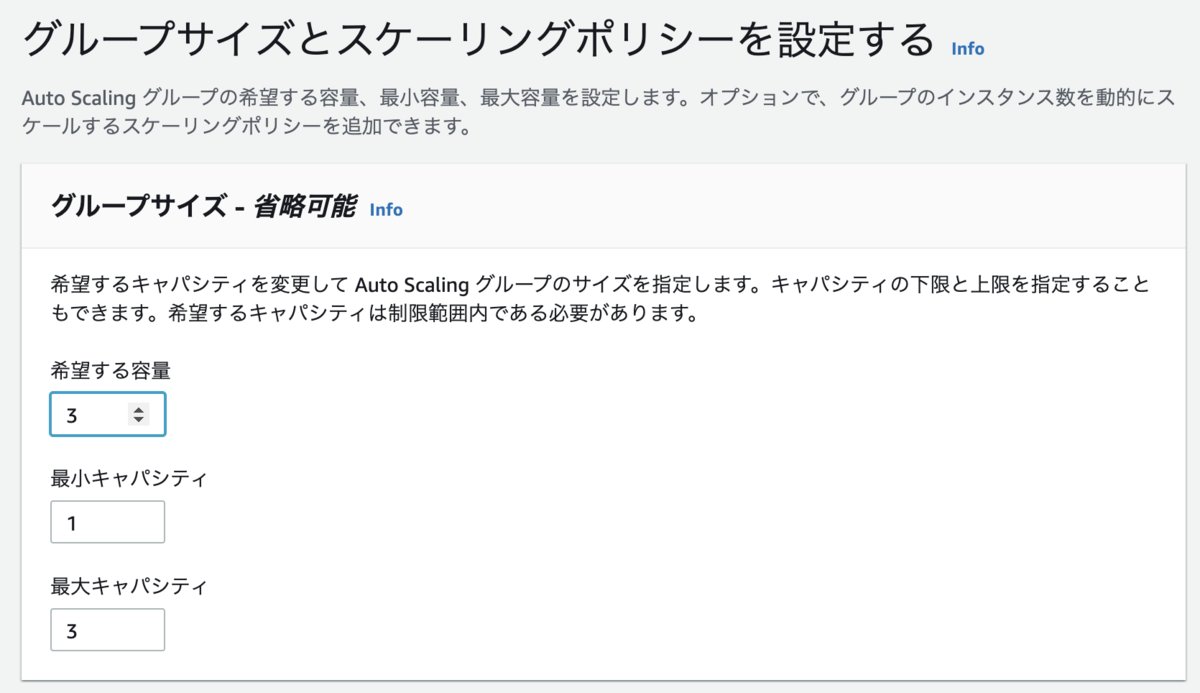
最大最小数を設定する。とりあえず3台動くように設定してみる。

EC2インスタンスの一覧で3台起動したことを確認できた。
オンデマンドインスタンスとスポットインスタンスの比率の調整がイマイチだったので、全部オンデマンドで立ち上がってしまいましたが、10台立ち上げたら、2〜3台がスポットインスタンスになっていたはず。
最初に設定するオンデマンドインスタンスの1台以上にしておけば、残りは全てスポットに当てるなどの設定をしてもいいかもしれない。この辺は運用見ながら調整していけばいいところなので、稼働が始まったら動きを観察して決めていけばいいかな。
また、起動テンプレートでは、AMIに変更があった場合にテンプレート側でバージョン管理ができて、起動設定のようにAMIが変わるたびにAutoScalingへのアタッチをやり直す必要もないので、管理コストも少し減りそうな予感。
EC2のAutoScalingよりも最近はサーバレスのLambdaとかコンテナベースのECSとかが主流になってきてそうだから、使う機会も減ってくるかもしれないけど、コスト削減には起動テンプレートは知っておいた方が良いかなと思います。